

Let's talk about pages. You know, like this

or infinite scrolling pages like this
Because we never want to give our website visitors all of our data, we present them in pages and let users load more as they please.
One method of paging, AKA pagination, in SQL that's easy is to limit a query to a certain number and when you want the next page, set an offset.
For example, here's a query for the second page of a blog
SELECT * from posts
ORDER BY created_at
LIMIT 10
OFFSET 10
However, for larger databases, this is not a good solution.
To demonstrate, I created a database and filled it 2,000,000 tweets. Well, not real tweets but just rows of data.
The database is on my laptop and is only 500mb in size so don't worry too much about the specific numbers in my results but what they represent.
First, I'm going to explain why using offset for pagination is not a good idea, and then present a few better ways of doing pagination.
Offset Pagination
Here's a graph showing how much time it takes to get each page. Notice that as the page number grows, the time needed to get that page increases linearly as well.

Results:
200,000 rows returned
~17.7s
~11,300 rows per second
** unable to paginate all 2 million rows under 5 minutes
This is because the way offsets works are by counting how many rows it should skip then giving your result. In other words, to get the results from rows 1,000 to 1,100 it needs to scan through the first 1,000 and then throw them away. Doesn't that seem a bit wasteful?
And that's not the only reason why offset is bad. What if in the middle of paging, another row is added or removed? Because the offset counts the rows manually for each page, it could under count because of the deleted row or over count because of a new row. Querying through offset will result in duplicate or missing results if your data is ever-changing.
There are better ways to paginate though! Here's one
Order Based Pagination
You can page on pretty much anything you can order your data by.
For example, If you have an increasing id you can use it as a cursor to keep track of what page you were on. First, you get your results, then use the id of the last result to find the next page.
SELECT * FROM tweet
WHERE id <= $last_id
ORDER BY id DESC
LIMIT 100
2,000,000 rows returned
~4.2s
~476,000 rows per second
This method is not only much faster but is also resilient to changing data! It doesn't matter if you deleted a row or added a new one since the pagination starts right where it left off.
Here's another graph showing the time it takes to page through 2 million rows of data, 100 rows at a time. Notice that it stays consistent!
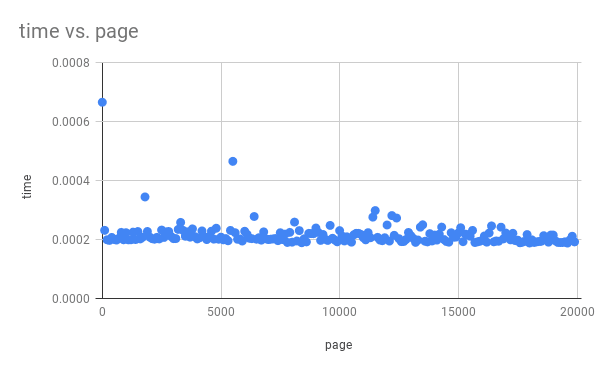
The trade-off is that it cannot go to an arbitrary page, because we need the id to find the page. This is is a great trade-off for infinite scrolling websites like Reddit and Twitter.
Time Pagination
Here's a more practical example of pagination based on the created_at field.
It has the same advantages and one drawback as ID pagination. However, you will need to add an index for (created_at, id) for optimal performance. I included id as well to break the tie on tweets created at the same time.
CREATE INDEX on tweet (created_at, id)
SELECT * from tweet
WHERE (created_at, id) <= ($prev_create_at, $prev_id)
ORDER BY created_at DESC, id DESC
LIMIT 100
2,000,000 rows returned
~4.70s
~425,000 rows per second
Conclusion
Should you really stop using OFFSET in your SQL queries? Probably.
Practically, however, you could be completely fine with slightly slower results since users won't be blazing through your pages. It all depends on your system and what trade-offs you're willing to make to get the job done.
I think offset has its place but not as a tool for pagination. It is much slower and less memory efficient than its easy alternatives. Thanks for reading!
✌🏾



















This is exactly right. More pertinently, ORMs should be providing this manner of pagination by default. The other reason is because if database rows are inserted inbetween queries, the pagination will start to overlap.