About: Software Developer, Programmer, ML Enthusiast, Exploring New Tech every day.
Location:
Gurgaon, India
Joined:
Jul 1, 2019
Add Pipeline Resolvers in AWS Amplify
Publish Date: Jul 18 '20
38 4
AWS AppSync and AWS Amplify make it easy for anyone to build Web Application (or iOS/Android Applications) without having to manage the underlying infrastructure. Developers can focus on building their front-end web application while AppSync and Amplify handles the heavy-lifting on the backend infrastructure side.
What are pipeline resolvers?
AWS AppSync executes resolvers on a GraphQL field. In some cases, applications require executing multiple operations to resolve a single GraphQL field. With pipeline resolvers, developers can now compose operations (called Functions or Pipeline Functions) and execute them in sequence. Pipeline resolvers are useful for applications that, for instance, require performing an authorization check before fetching data for a field.
What are we building?
In this tutorial, you'll learn how to add a pipeline resolver in an AWS Amplify application. You'll build a new AWS Amplify backend with:
A User model.
A signupUser mutation that uses a pipeline resolver.
A lambda function that takes the password field from input data and replaces it with a hashed password for security. It will be part of the pipeline resolver for signupUser mutation.
Prerequisites
To complete this tutorial, you will need:
Node.js(>=10.x) and NPM(>=6.x) installed. Download from here.
An AWS account. If you don't have one, you can create here.
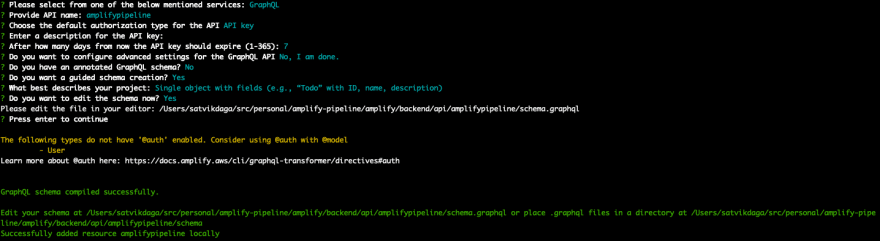
Save the file and hit enter in your terminal window. If no error messages are thrown this means the transformation was successful and schema is valid.
Step 4 - Add a Lambda function to hash password
Create a lambda function that takes the password field from the input and returns hashed password in response.
Run the following command.
$amplify add function
Complete the relevant prompts.
Update the source code of the amplifypipelineHashPassword lambda function(i.e. index.js).
constbcrypt=require('bcryptjs');exports.handler=async(event)=>{// get password field from inputconst{password}=event.arguments.input;// use bcrypt to hash passwordconsthash=awaitbcrypt.hash(password,10);// return the hashed password as responsereturn{hash,};};
Add bcryptjs node library to the lambda function. Run this from the root directory of your React app.
Now you can deploy the API and lambda function to AWS.
$amplify push
Step 5 - Add user signup mutation
You will add a custom mutation called signupUser that creates a new user.
For this, you will need to add a custom resolver that targets the User table.
Here instead of a custom resolver, you'll add a pipeline resolver and a pipeline function that targets the UserTable.
Add a pipeline resolver and pipeline function resource to a stack(like CustomResources.json) in the stacks/ directory. The DataSourceName is auto-generated. In most cases, it’ll look like {MODEL_NAME}Table. To confirm the data source name, you can verify it from within the AppSync Console (amplify console api) and clicking on the Data Sources tab.
Write the pipeline resolver templates in the resolvers directory. These are the before and after mapping templates that are run in the beginning and the end of the pipeline respectively.
Write the pipelineFunction templates for MutationCreateUserFunction resource. Create a pipelineFunctions folder if it doesn't exist in your API resource. From your app root, run the following command.
In the req template, you access the previous function result to get the hashed password. You then replace the password field in the input with the hashed password. So the new user created will save the hashed password in the database instead. Note: In a pipeline function, you can access the results of the previous pipeline function as $ctx.prev.result.
## pipelineFunctions/MutationCreateUserFunction.req.vtl
## [Start] Replace password in input with hash
## Set hash from previous pipeline function result
#set( $hash = $ctx.prev.result.hash )
## Set the password field as hash if present
$util.qr($context.args.input.put("password", $util.defaultIfNull($hash, $context.args.input.password)))
## [End] Replace password in input with hash
## [Start] Set default values. **
$util.qr($context.args.input.put("id", $util.defaultIfNull($ctx.args.input.id, $util.autoId())))
#set( $createdAt = $util.time.nowISO8601() )
## Automatically set the createdAt timestamp. **
$util.qr($context.args.input.put("createdAt", $util.defaultIfNull($ctx.args.input.createdAt, $createdAt)))
## Automatically set the updatedAt timestamp. **
$util.qr($context.args.input.put("updatedAt", $util.defaultIfNull($ctx.args.input.updatedAt, $createdAt)))
## [End] Set default values. **
## [Start] Prepare DynamoDB PutItem Request. **
$util.qr($context.args.input.put("__typename", "User"))
#set( $condition = {
"expression": "attribute_not_exists(#id)",
"expressionNames": {
"#id": "id"
}
} )
#if( $context.args.condition )
#set( $condition.expressionValues = {} )
#set( $conditionFilterExpressions = $util.parseJson($util.transform.toDynamoDBConditionExpression($context.args.condition)) )
$util.qr($condition.put("expression", "($condition.expression) AND $conditionFilterExpressions.expression"))
$util.qr($condition.expressionNames.putAll($conditionFilterExpressions.expressionNames))
$util.qr($condition.expressionValues.putAll($conditionFilterExpressions.expressionValues))
#end
#if( $condition.expressionValues && $condition.expressionValues.size() == 0 )
#set( $condition = {
"expression": $condition.expression,
"expressionNames": $condition.expressionNames
} )
#end
{
"version": "2017-02-28",
"operation": "PutItem",
"key": #if( $modelObjectKey ) $util.toJson($modelObjectKey) #else {
"id": $util.dynamodb.toDynamoDBJson($ctx.args.input.id)
} #end,
"attributeValues": $util.dynamodb.toMapValuesJson($context.args.input),
"condition": $util.toJson($condition)
}
## [End] Prepare DynamoDB PutItem Request. **
In the res template, convert to JSON and return the result.
To add a lambda function to an AppSync pipeline resolver, you need:
A lambda function. You already created the hash password lambda function.
An AppSync DataSource HashPasswordLambdaDataSource that targets the lambda function.
An AWS IAM role HashPasswordLambdaDataSourceRole that allows AppSync to invoke the lambda function on your behalf to the stack’s Resources block.
A pipeline function InvokeHashPasswordLambdaDataSource resource that invokes the HashPasswordLambdaDataSource.
Update MutationSignupUserResolver resource block and add lambda function in the pipeline.
Here is the complete resources block in a stack(like CustomResources.json) in the stacks/ directory.
The password of the newly created user is hashed.
First, the password field is hashed by the HashPasword Lambda function, and then a user with hashed password is created by the pipeline resolver for signupUser mutation.
Note: You can also test your app locally by running the following command amplify mock. Click here for more details.
Conclusion
Congratulations! You have successfully added a pipeline resolver to your AWS Amplify application. Now you can easily add a pipeline resolver for any graphQL operation.
You can find the complete source code for this tutorial on GitHub.
Great post, exactly what I was looking for! When we create a DynamoDB table with the @model annotation, Amplify creates the create/update/delete mutations with the VTL templates for us. Is it possible to use these auto-generated templates in a pipeline resolver, so that we can invoke a lambda before the original create/update VTL template?
It's not possibly right now as those templates are linked to a mutation resolver and not a pipeline function in the cloudformation stack generated by amplify. You will need to create a pipeline function configuration as mentioned in the article.
But there is a way using which amplify creates pipeline based resolvers for all queries and mutations although it's not supported by default. Check this link docs.amplify.aws/cli/reference/fea...
Please note it's an experimental feature currently.
Hope it helps!









Great post, exactly what I was looking for! When we create a DynamoDB table with the @model annotation, Amplify creates the create/update/delete mutations with the VTL templates for us. Is it possible to use these auto-generated templates in a pipeline resolver, so that we can invoke a lambda before the original create/update VTL template?