About: I am a kind of guy who likes programming at its core; excellent communication as well as leadership skills. Detail oriented and organised professional.
Location:
Ahmedabad, Gujarat
Joined:
Nov 26, 2020
Next.js 14 Booking App with Live Data Scraping using Scraping Browser
In the ever-evolving landscape of web development, the ability to efficiently gather, process, and display data from external sources has become increasingly valuable. Whether for market research, competitive analysis, or customer insights, web scraping plays a crucial role in unlocking the vast potential of the internet's data.
This blog post introduces a comprehensive guide to building a robust Next.js application designed for scraping flight data from Kayak, one of the leading travel search engines. By leveraging the power of Next.js alongside modern technologies such as BullMQ, Redis, and Puppeteer.
🚀 Next.js 14 App Directory with Tailwind CSS - Experience the sleek and modern UI powered by the latest Next.js 14 and styled with Tailwind CSS for that perfect look and feel.
🔗 API Routes & Server Actions - Dive into seamless backend integration with Next.js 14's API routes and server actions ensuring efficient data handling and server-side logic execution.
🕷 Scraping with Puppeteer Redis and BullMQ - Harness the power of Puppeteer for advanced web scraping with Redis and BullMQ managing queues and jobs for robust backend operations.
🔑 JWT Tokens for Authentication and Authorization - Secure your app with JWT tokens providing a reliable method for authentication and authorization across your platform.
💳 Stripe for Payment Gateways - Integrate Stripe for seamless payment processing enabling secure and easy transactions for booking trips flights and hotels.
✈️ Book Trips Flights and Hotels with Stripe Payment Gateway - Make your travel booking experience effortless with our Stripe-powered payment system.
📊 Scrape Live Data from Multiple Websites - Stay ahead with real-time data scraping from multiple sources keeping your app updated with the latest information.
💾 Store the Scraped Data in PostgreSQL with Prisma - Leverage PostgreSQL and Prisma for efficient storage and management of your scraped data ensuring reliability and speed.
🔄 Zustand for State Management - Enjoy smooth and manageable state management in your app with Zustand simplifying state logic and enhancing performance.
😈 Best Feature of the App - Scraping the Unscrapable Data with Bright Data's Scraping Browser.
Bright Data's Scraping Browser provides us with an automatic captcha-solving feature that helps us scrape the un-scrapable data.
Step 1: Setting Up the Next.js Application
Create a Next.js App: Start by creating a new Next.js app if you haven't already. You can do this by running the following command in your terminal:
npx create-next-app@latest booking-app
Navigate to Your App Directory: Change into your newly created app directory:
cd booking-app
Step 2: Installing Required Packages
You'll need to install several packages, including Redis, BullMQ, and Puppeteer Core. Run the following command to install them:
npm install ioredis bullmq puppeteer-core
ioredis is a robust Redis client for Node.js, enabling communication with Redis.
bullmq manages job and message queues with Redis as the backend.
puppeteer-core allows you to control an external browser for scraping purposes.
Step 3: Setting Up Redis Connection
Create a file (e.g., redis.js) in a suitable directory (e.g., lib/) to configure the Redis connection:
// lib/redis.jsimportRedisfrom'ioredis';// Use REDIS_URL from environment or fallback to localhostconstREDIS_URL=process.env.REDIS_URL||'redis://localhost:6379';constconnection=newRedis(REDIS_URL);export{connection};
Step 4: Configuring BullMQ Queue
Set up the BullMQ queue by creating another file (e.g., queue.js) in the same directory as your Redis configuration:
2.Create a Worker for Job Processing: In your application, create a file (instrumentation.js) to handle job processing. This worker will use Puppeteer for scraping tasks:
Before setting up Bright Data Scraping Browser let's talk about what a scraping browser is.
What is Bright Data's scraping browser?
Bright Data's Scraping Browser is a cutting-edge tool for automated web scraping, designed to seamlessly integrate with Puppeteer, Playwright, and Selenium. It offers a suite of website unblocking features, including proxy rotation, CAPTCHA solving, and more, to enhance scraping efficiency. Ideal for complex web scraping requiring interactions, it allows scalability by hosting unlimited browser sessions on Bright Data’s infrastructure. For more details, visit Bright Data.
Step 1: Navigate to Bright Data's Website
Begin by heading over to Brightdata.com. This is your gateway to accessing the wealth of web scraping resources and tools offered by Bright Data.
Step 2: Create an Account
Once you're on Bright Data's website, sign up to create a new account. You'll be prompted to enter essential information to get your account up and running.
Step 3: Select Your Product
On the product selection page, look for the Proxies & Scraping Infrastructure product. This product is specifically designed to meet your web scraping needs, offering powerful tools and features for data extraction.
Step 4: Add a New Proxy
Within the Proxies & Scraping Infrastructure page, you'll find an "add new button." Click on this to start the process of adding a new scraping browser to your toolkit.
Step 5: Choose the Scraping Browser
A dropdown list will appear, from which you should select the scraping browser option. This tells Bright Data that you intend to set up a new scraping browser environment.
Step 6: Name Your Scraping Browser
Give your new scraping browser a unique name. This helps in identifying and managing it later, especially if you plan to use multiple browsers for different scraping projects.
Step 7: Add the Browser
After naming your browser, click on the "add" button. This action finalizes the creation of your new scraping browser.
Step 8: View Your Scraping Browser Details
Upon adding your scraping browser, you will be directed to a page where you can see all the details of your newly created scraping browser. This information is crucial for integration and use.
Step 9: Access Code and Integration Examples
Look for the "check out code and integration examples" button. Clicking this will provide you with a comprehensive view of how to integrate and use your scraping browser across multiple programming languages and libraries. This resource is invaluable for developers looking to customize their scraping setup.
Step 10: Integrate Your Scraping Browser
Finally, copy the SRS_WS_ENDPOINT variable. This is a critical piece of information that you will need to integrate into your source code, allowing your applications to communicate with the scraping browser you've just set up.
By following these detailed steps, you have successfully created a scraping browser within Bright Data's platform, ready to tackle your web scraping tasks. Remember, Bright Data offers extensive documentation and support to help you maximize your scraping projects' efficiency and effectiveness. Whether you're gathering market intelligence, conducting research, or monitoring competitive landscapes, your newly set up scraping browser is a powerful tool in your data collection arsenal.
Step 7: Implementing the Scraping Logic with Puppeteer
Continuing from where we left off in setting up our Next.js application for scraping flight data, the next critical step is to implement the actual scraping logic. This process involves utilizing Puppeteer to connect to a browser instance, navigate to the target URL (in our case, Kayak), and scrape the necessary flight data. The code snippet provided outlines a sophisticated method for achieving this goal, seamlessly integrating with our previously established BullMQ worker setup. Let's break down the components of this scraping logic and understand how it fits into our application.
Establishing a Connection to the Browser
The first step in our scraping process is to establish a connection to the browser through Puppeteer. This is accomplished by utilizing the puppeteer.connect method, which connects to an existing browser instance using a WebSocket endpoint (SBR_WS_ENDPOINT). This environment variable should be set to the WebSocket URL of the scraping browser service you're using, such as Bright Data:
Opening a New Page and Navigating to the Target URL
Once connected, we create a new page in the browser and navigate to the target URL specified in the job data. This URL is the specific Kayak search result page from which we intend to scrape flight data:
The core of our logic lies in scraping the flight data from the page. We achieve this by using page.evaluate, a Puppeteer method that allows us to run scripts in the context of the browser. Within this script, we wait for the necessary elements to load and then proceed to collect flight information:
Flight Selector: We target elements with the class .nrc6-wrapper, which contain flight details.
Data Extraction: For each flight element, we extract details such as the airline logo, departure and arrival times, flight duration, airline name, and price. The departure and arrival times are cleaned to remove unnecessary numeric values at the end, ensuring we capture the time accurately.
Price Processing: The price is extracted as an integer after removing all non-numeric characters, ensuring it can be used for numerical operations or comparisons.
The extracted data is structured into an array of flight objects, each containing the details mentioned above:
constscrappedFlights=awaitpage.evaluate(async ()=>{// Data extraction logicconstflights=[];// Process each flight element// ...returnflights;});
Error Handling and Cleanup
Our scraping logic is wrapped in a try-catch block to handle any potential errors gracefully during the scraping process. Regardless of the outcome, we ensure the browser is closed properly in the finally block, maintaining resource efficiency and preventing potential memory leaks:
constSBR_WS_ENDPOINT=process.env.SBR_WS_ENDPOINT;exportconstregister=async ()=>{if (process.env.NEXT_RUNTIME==="nodejs"){const{Worker}=awaitimport("bullmq");constpuppeteer=awaitimport("puppeteer");const{connection}=awaitimport("./lib/redis");const{importQueue}=awaitimport("./lib/queue");newWorker("importQueue",async (job)=>{constbrowser=awaitpuppeteer.connect({browserWSEndpoint:SBR_WS_ENDPOINT,});try{constpage=awaitbrowser.newPage();console.log("in flight scraping");console.log("Connected! Navigating to "+job.data.url);awaitpage.goto(job.data.url);console.log("Navigated! Scraping page content...");constscrappedFlights=awaitpage.evaluate(async ()=>{awaitnewPromise((resolve)=>setTimeout(resolve,5000));constflights=[];constflightSelectors=document.querySelectorAll(".nrc6-wrapper");flightSelectors.forEach((flightElement)=>{constairlineLogo=flightElement.querySelector("img")?.src||"";const[rawDepartureTime,rawArrivalTime]=(flightElement.querySelector(".vmXl")?.innerText||"").split(" – ");// Function to extract time and remove numeric values at the endconstextractTime=(rawTime:string):string=>{consttimeWithoutNumbers=rawTime.replace(/[0-9+\s]+$/,"").trim();returntimeWithoutNumbers;};constdepartureTime=extractTime(rawDepartureTime);constarrivalTime=extractTime(rawArrivalTime);constflightDuration=(flightElement.querySelector(".xdW8")?.children[0]?.innerText||"").trim();constairlineName=(flightElement.querySelector(".VY2U")?.children[1]?.innerText||"").trim();// Extract priceconstprice=parseInt((flightElement.querySelector(".f8F1-price-text")?.innerText||"").replace(/[^\d]/g,"").trim(),10);flights.push({airlineLogo,departureTime,arrivalTime,flightDuration,airlineName,price,});});returnflights;});}catch (error){console.log({error});}finally{awaitbrowser.close();console.log("Browser closed successfully.");}},{connection,concurrency:10,removeOnComplete:{count:1000},removeOnFail:{count:5000},});}};
Step 8: Flight Search Feature
Building upon our flight data scraping functionality, let's integrate a comprehensive flight search feature into our Next.js application. This feature will provide users with a dynamic interface to search for flights by specifying the source, destination, and date. Leveraging the powerful Next.js framework alongside a modern UI library and state management, we create an engaging and responsive flight search experience.
Key Components of the Flight Search Feature
Dynamic City Selection: The feature includes an autocomplete functionality for source and destination inputs, powered by a pre-defined list of city-airport codes. As users type, the application filters and displays matching cities, enhancing the user experience by making it easier to find and select airports.
Date Selection: Users can select their intended flight date through a date input, providing flexibility in planning their travel.
Scraping Status Monitoring: After initiating a scraping job, the application monitors the job's status through periodic API calls. This asynchronous checking allows the app to update the UI with the status of the scraping process, ensuring users are informed of the progress and results.
After successfully scraping flight data, the next crucial step is to present these results to the users in a user-friendly manner. The Flights component in your Next.js application is designed for this purpose.
The sections and code snippets shared above represent just a fraction of the full functionality and code necessary to build a robust flight data scraping and search application using Next.js. To grasp the entirety of this project, including advanced features, optimizations, and best practices, I invite you to dive deeper through my comprehensive resources available online.
Watch the Detailed Explanation on YouTube
For a step-by-step video guide that walks you through the development process, coding nuances, and functionality of this application, check out my YouTube video. This tutorial is designed to provide you with a deeper understanding of the concepts, allowing you to follow along at your own pace and gain valuable insights into Next.js application development.
Explore the Full Code on GitHub
If you're eager to explore the code in its entirety, head over to my GitHub repository. There, you'll find the complete codebase, including all the components, utilities, and setup instructions you need to get this application running on your own machine.
Travel Planner App with Live Web Scraping from various sources using Bright Data scraping browser.
Project Screenshots:
🧐 Features
Here are some of the project's best features:
🚀 Next.js 14 App Directory with Tailwind CSS - Experience the sleek and modern UI powered by the latest Next.js 14 and styled with Tailwind CSS for that perfect look and feel.
🔗 API Routes & Server Actions - Dive into seamless backend integration with Next.js 14's API routes and server actions ensuring efficient data handling and server-side logic execution.
🕷 Scraping with Puppeteer Redis and BullMQ - Harness the power of Puppeteer for advanced web scraping with Redis and BullMQ managing queues and jobs for robust backend operations.
🔑 JWT Tokens for Authentication and Authorization - Secure your app with JWT tokens providing a reliable method for authentication and authorization across your platform.
Building a comprehensive application like the flight data scraping and search tool with Next.js showcases the power and versatility of modern web development tools and frameworks. Whether you're a seasoned developer looking to refine your skills or a beginner eager to dive into web development, these resources are tailored to support your journey. Watch the detailed tutorial on YouTube, explore the full code on GitHub, and join the conversation to enhance your development expertise and contribute to the vibrant developer community.
I find that using Puppeteer or any headless browser for scraping in most cases is such an overkill. It's good for automated end to end testing, but for scraping data there are simpler and much more performant approaches.
In your case, you're grabbing data from Kayak. After a quick inspection in the network tab and playing around with the website, they return us all the data we need in the initial document HTML and we can use their routing as an API:
The above url gives us back flights between London and New York, between the two dates specified. We can also sort the data the way we want it.
Now, a simple fetch method to get the initial HTML is sufficient, this way we avoid all other data that comes through after initial page load (analytics, client side fetches, css and js scripts etc.)
That initial document HTML has javascript code baked into it, with all the data hydrated in json format which we can extract easily using any html parsing library.
Bonus to the above, I would remove zustand, and not store the data client side like that, then the component that display flights doesn't need to an client side component. We can achieve getting all the data with server components and make the app stateless that's reliant on the backend to get the data.
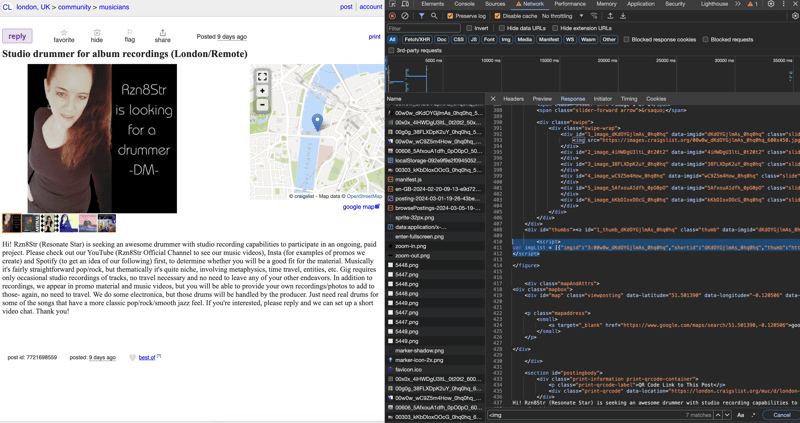
This doesn't always work. For instance, you cannot do this with Craigslist gallery as Craigslist builds the DOM dynamically. In my project, I ended up using Puppeteer.
The swiper element looks like some Jquery thing that dynamically adds images.
All the data for the images URLs are baked in the initial HTML:
In any case, if the above wasn't a thing, then you would listen to xhr calls on network tab to see where the images are coming from server side to try "hack" around it.
in 90% of cases puppeeter is a overkill, there comes 10% of times where it isnt
I was talking about the gallery, which is a list of posts for a given category. Fetching used to return just this:
<noscript id="no-js"><div>
<p>We've detected that JavaScript is not enabled in your browser.</p>
<p>You must enable JavaScript to use craigslist.</p>
</div></noscript>
<div id="unsupported-browser">
<p>We've detected you are using a browser that is missing critical features.</p>
<p>Please visit craigslist from a modern browser.</p>
</div>
Looks like this has changed in the past few months, and I am now able to get the list of posts just with curl, so as you say using Puppeteer for this is overkill (and it is slow). But a few months ago my curl request would only return the HTML above.
HTML shown in the browser via View Page Source was the same. I found scripts that downloaded a bunch of cryptic JSON files and used them to build the DOM.
actually if you play with meta search sites like kayak,expedia,etc for a long time, you'd probably find their webapp very tricky with such hacks. you'd either be blocked by cloudflare or ratelimited frequently. i am not saying using playwright would workaround completely but it does go through at a higher ratio.
Anyway, I found author's solution kind of great for a homelab showcase, though definitely needs lots of polishing for serious usage. Am I understanding right, Kishan?
















.png)






This is a great in-depth article, brother! Thanks! 🙌