This repository focuses on cloud computing and demonstrates how to set up virtual machines, S3, and other services using LocalStack. It provides a comprehensive guide to simulating AWS services locally for development and testing purposes.
Cloud-Computing
This repository focuses on cloud computing and demonstrates how to set up virtual machines, S3, and other services using LocalStack. It provides a comprehensive guide to simulating AWS services locally for development and testing purposes.
AWS Command Line Interface (CLI) is a powerful tool that allows users to interact with AWS services directly from the terminal. It simplifies managing cloud resources by providing commands for a wide range of AWS services, enabling tasks such as provisioning, managing, and automating workflows with ease.
LocalStack is a fully functional, local testing environment for AWS services. It enables developers to simulate AWS services on their local machines, facilitating the development and testing of cloud-based applications without needing access to an actual AWS account.
we talked about cloud networking, exploring how to set up secure and efficient connections with VPCs, subnets, and security groups.
Now, we move on to the backbone of cloud computing: Serverless Lambda — (not your math lambda! 😉)
We’ll explore how AWS Lambda lets you run code without worrying about servers, scaling, or heavy lifting.
Stay tuned — it’s time to go serverless and unleash the power of the cloud! ⚡☁️
What is Serverless Computing and AWS Lambda?
What is Serverless Computing?
Serverless computing is a cloud computing model where the cloud provider manages the underlying infrastructure. The term "serverless" doesn’t mean servers are absent; rather, it means developers don't need to manage them. The provider handles provisioning, scaling, and maintenance, allowing developers to concentrate solely on building and deploying code.
What is AWS Lambda?
AWS Lambda is a serverless compute service by Amazon Web Services (AWS) that allows users to run code without provisioning or managing servers. Developers simply focus on writing application logic, while AWS automatically handles server infrastructure, scaling, and maintenance.
AWS Lambda is a key example of serverless computing. It lets you execute code in response to events—such as HTTP requests, file uploads, or database updates—without worrying about managing servers. Lambda functions integrate seamlessly with services like API Gateway, S3, DynamoDB, and more.
Key Features of AWS Lambda
Event-Driven Execution
Functions are triggered by events like HTTP requests, S3 uploads, or database changes.
Automatic Scaling
Lambda automatically scales to handle varying workloads, from a few requests to thousands per second.
Cost-Efficient
You only pay for the compute time your code uses, rather than pre-paying for idle servers.
No Server Management
AWS handles all backend server management, freeing developers from infrastructure concerns.
Multiple Language Support
Supports Python, Node.js, Java, C#, Go, Ruby, and more.
Stateless Functions
Lambda functions are stateless; they do not retain data between invocations. External storage like databases is used for persistence.
Common Use Cases of AWS Lambda
Real-Time File Processing
Process images, audio, or documents immediately upon upload to S3.
Microservices Architecture
Build small, independent services that can be deployed and scaled individually.
API Backends
Power RESTful APIs by integrating Lambda with API Gateway.
Data Processing and ETL Tasks
Transform or move data automatically in response to database events or file uploads.
Automation and Scheduled Tasks
Schedule regular tasks like backups, cleanups, or report generation without server setup.
Event-Driven Applications
React to events instantly, such as sending alerts when a new user signs up.
Visual Understanding of AWS Lambda
First Image: AWS Lambda Overview
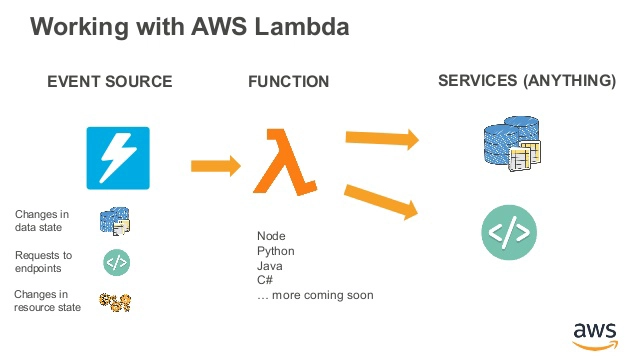
This image provides a snapshot of AWS Lambda's serverless model: developers upload code, and AWS automatically manages provisioning, scaling, and monitoring. Lambda seamlessly interacts with other AWS services, enabling event-driven solutions.
Second Image: AWS Lambda Workflow and Integrations
This deeper dive illustrates how Lambda connects with services like API Gateway, S3, and DynamoDB, showing its ability to handle real-time data processing, microservices communication, and backend automation.
Pros and Cons of AWS Lambda
Pros
Cost-Effective: Only pay for what you use; no charge when idle.
Automatic Scaling: Handles sudden spikes in traffic effortlessly.
Reduced Operational Overhead: No need to manage, patch, or scale servers.
Fast Deployment: Applications can be updated and deployed rapidly.
Security Integration: Works with AWS Identity and Access Management (IAM) for controlled access.
Cons
Cold Start Latency: A delay may occur if a function is triggered after being idle.
Execution Time Limit: Functions can run a maximum of 15 minutes per invocation.
Statelessness: Developers must handle persistence externally.
Resource Constraints: Limited memory and compute power compared to traditional servers.
Practical Real-World Example:
Imagine a photo-sharing application:
A user uploads a photo to an S3 bucket.
An AWS Lambda function triggers automatically to resize the image.
The resized images are saved back to S3 for use across devices.
No server provisioning, scaling, or manual monitoring is required—the entire pipeline runs seamlessly, triggered by simple events.
Real Companies Using AWS Lambda 🚀
Netflix 🎬: Uses Lambda for real-time file encoding, system monitoring, and automation—processing billions of video streams without managing servers.
Airbnb 🏠: Relies on Lambda for image processing, automated backups, and real-time data analysis.
Coca-Cola 🥤: Powers vending machine transactions with Lambda, paying only per use—cutting infrastructure costs.
Reuters 📰: Uses Lambda to resize and format images instantly for fast publishing in their global news delivery system.
iRobot 🤖: Employs Lambda to manage data from its connected home devices, enabling seamless IoT integration and event-driven automation.
Simple Lambda Function with LocalStack
Step-by-Step Creation of a Lambda Function with LocalStack
1. Creating the Lambda Function:
To create a Lambda function using LocalStack, the first step involves writing the Lambda function code. The function will be triggered by an event and should return a simple response.
Example Lambda Function Code (lambda_function.py):
deflambda_handler(event,context):return{'statusCode':200,'body':'Hello from LocalStack Lambda!'}
This function will output a basic response with a 200 OK status code when invoked.
2. Deploying the Lambda Function:
Before deploying the Lambda function, the Python code needs to be packaged into a ZIP file. This ZIP file will be used to deploy the function to LocalStack.
Steps for Packaging the Lambda Function (on Windows):
Navigate to the directory where your lambda_function.py file is located.
Right-click the lambda_function.py file and select Send to > Compressed (zipped) folder from the context menu.
Rename the resulting .zip file to function.zip.
After the Lambda function is packaged, it is ready for deployment.
3. Checking the Function Creation Status:
After the Lambda function is deployed, its status can be checked to ensure it has been successfully created. Initially, the status might be in a Pending state, indicating that LocalStack is still processing the request to create the function.
If the function is still in the Pending state, wait for a few moments before checking again. Once the function’s status is Active or Available, it can be invoked.
4. Invoking the Lambda Function:
After the function is in the Active state, it can be invoked using the AWS CLI. The invocation will trigger the Lambda function and return the response in a file (in this case, output.txt).
It’s common to face issues when setting up Lambda functions with LocalStack. For example, if LocalStack is unable to fetch the required Lambda runtime (in this case, Python 3.8), the creation will fail. In the example provided, the Lambda function was in a Failed state with the error message:
State: Failed
StateReason: Error while creating lambda: public.ecr.aws/lambda/python:3.8
StateReasonCode: InternalError
This indicates that LocalStack could not retrieve the Python 3.8 runtime image from the repository (public.ecr.aws/lambda/python:3.8). The error is internal, likely caused by an issue with LocalStack’s ability to access or fetch the necessary container image from the registry.
Why Did the Lambda Function Fail?
The Lambda function failed due to an issue where LocalStack was unable to fetch the Python 3.8 runtime from the expected image repository (public.ecr.aws/lambda/python:3.8). This led to an InternalError.
State: Failed
StateReason: Error while creating lambda: public.ecr.aws/lambda/python:3.8
StateReasonCode: InternalError
This error indicates that LocalStack could not access or retrieve the Lambda runtime, which caused the function creation process to fail.
Troubleshooting and Resolving the issue using Docker
How to Resolve This Issue?
1. Ensure the Correct Lambda Runtime is Available
LocalStack uses Docker-based Lambda runtimes. To ensure that LocalStack can properly run the Lambda function, it is necessary to manually pull the required Docker image. In this case, LocalStack requires the Python 3.8 Lambda runtime.
To resolve this, follow these steps to pull the necessary Docker image:
docker pull public.ecr.aws/lambda/python:3.8
Once this command is executed, Docker will download the required Python 3.8 Lambda image. Below is the expected output when the image is successfully pulled:
To confirm that the image has been successfully downloaded, use the following command to list all the Docker images present on the system:
docker images
The output should list the public.ecr.aws/lambda/python:3.8 image among other available images. Below is an example of the output you should expect:
C:\Users\rawat\Documents\8 SEMESTER\Cloud
Computing\Lab\Experiment 5\Codes>docker images
REPOSITORY TAG IMAGE ID
CREATED SIZE
flask-app latest 269bf42596ed
12 days ago 126MB
<none> <none> 44b808030263
2 weeks ago 126MB
<none> <none> 063caad47b0a
2 weeks ago 126MB
localstack/localstack latest b686f3948f42
3 weeks ago 1.18GB
hello-world latest 74cc54e27dc4
3 weeks ago 10.1kB
public.ecr.aws/lambda/python 3.8 348b357f1c82
4 weeks ago 575MB
This verifies that the image is available locally.
3. Retry the Lambda Function Creation
Once the Python 3.8 Lambda runtime image is available locally, LocalStack should be able to retrieve the runtime successfully. Retry the Lambda function creation process, and it should deploy without issues.
By following these steps, the error related to the missing Lambda runtime will be resolved, ensuring that LocalStack can properly run the Lambda function without any further issues.
Running a Simple Lambda Function with LocalStack After Resolving Issues
Recreating and Invoking the Lambda Function with LocalStack
Step 1: Recreate the Lambda Function
The first step is to create a new Lambda function in LocalStack. To do so, the AWS CLI create-function command is used. This command tells LocalStack to create a Lambda function with the specified configurations.
Here’s a breakdown of what each part of the command does:
aws --endpoint-url=http://localhost:4566:
This specifies that the AWS CLI should interact with LocalStack rather than the actual AWS cloud. localhost:4566 is the default endpoint for LocalStack's services.
lambda create-function:
This is the AWS CLI command used to create a new Lambda function.
--function-name myLambdaFunction:
This specifies the name of the Lambda function being created. In this case, the function is named myLambdaFunction.
--runtime python3.8:
This sets the runtime for the Lambda function to Python 3.8. LocalStack uses Docker to run Lambda functions with specific runtimes, and Python 3.8 is chosen here.
This assigns an IAM role to the Lambda function. The execution_role is required for Lambda functions to execute. In LocalStack, this is a placeholder, and a specific role ARN is not needed for local execution.
--handler lambda_function.lambda_handler:
This specifies the function within the code to be executed when the Lambda function is invoked. The handler format is file_name.function_name, which tells LocalStack to look in the lambda_function.py file for the lambda_handler function to run.
--zip-file fileb://lambda_function.zip:
This points to the zip file containing the Lambda function code. The fileb:// prefix tells AWS CLI that the file is on the local file system. The lambda_function.zip file must contain the Python script (lambda_function.py).
Step 2: Invoke the Lambda Function
Once the function is created successfully, it can be invoked using the AWS CLI. This triggers the Lambda function and stores the output in a file.
Here’s a breakdown of what each part of the invoke command does:
aws --endpoint-url=http://localhost:4566:
Just like before, this specifies that the command should interact with LocalStack on the specified endpoint.
lambda invoke:
This AWS CLI command triggers the Lambda function and executes it.
--function-name myLambdaFunction:
This specifies the name of the Lambda function that should be invoked. In this case, it's myLambdaFunction, which was created in the previous step.
output.txt:
This is the file where the output of the Lambda function invocation will be stored. After the function runs, its response will be written to output.txt.
Step 3: View the Output
After invoking the Lambda function, the results are stored in the output.txt file. The type command in Windows can be used to display the contents of this file.
Command to View the Output:
type output.txt
This command displays the content of the output.txt file. The expected output looks like this:
{"statusCode": 200, "body": "Hello from LocalStack Lambda!"}
Explanation of the Output:
The content of the output.txt file is a JSON response returned by the Lambda function:
statusCode: 200:
This indicates that the Lambda function executed successfully and returned an HTTP status code of 200, which signifies a successful response.
body: "Hello from LocalStack Lambda!":
This is the body of the response. It contains the message "Hello from LocalStack Lambda!", which was defined in the Lambda function. This message is returned as part of the response when the function is triggered.
Summary of Commands and Outputs:
Recreate the Lambda Function: The create-function command defines the function, its runtime (Python 3.8), execution role, and handler function. It also links the Lambda function to the lambda_function.zip file containing the code.
Invoke the Lambda Function: The invoke command runs the Lambda function and stores the response in output.txt.
View the Output: The type command shows the contents of output.txt, which contains a JSON response indicating the Lambda function executed successfully.
By following these steps, the Lambda function is successfully created, invoked, and the output is captured and displayed.
Complex Lambda Function with Payload with LocalStack
Detailed Commands, Redeployment, and Output for Lambda Function with Payload Processing
Updated Lambda Function Code:
Here is the updated Lambda function code that processes a payload with an input event and performs some computations:
importjsonimportlogging# Set up logging for debugging and monitoring
logging.basicConfig(level=logging.INFO)logger=logging.getLogger()# Function versioning for tracking updates
VERSION="1.0.0"deflambda_handler(event,context):"""
Handles AWS Lambda execution by processing event data
and performing basic computations.
**Parameters:**
- event (dict): The input event data, expected to contain:
- `"name"` (str, optional): The name of the user.
Defaults to `"Guest"` if not provided.
- `"number"` (int, optional): A number to be processed.
Defaults to `0` if not provided.
- context (object): AWS Lambda context object
(not used in this function).
**Returns:**
- dict: JSON-formatted response with:
- `"message"` (str): Greeting message.
- `"processedNumber"` (int): The input number multiplied by 2.
- `"version"` (str): Function version identifier.
"""# Log event details for debugging
logger.info(f"Function invoked with event: {json.dumps(event)}")logger.info(f"Lambda function version: {VERSION}")# Extract 'name' from the event, defaulting to "Guest"
name=event.get("name","Guest")greeting=f"Hello, {name}!"# Extract 'number' from the event and process it
number=event.get("number",0)# Default to 0 if not provided
result=number*2# Double the input number
# Construct the response payload
response={"statusCode":200,# HTTP status code indicating success
"body":json.dumps({"message":greeting,# Greeting message
"processedNumber":result,# Computed number result
"version":VERSION,# Function version for tracking
}),}# Log response details before returning
logger.info(f"Returning response: {json.dumps(response)}")returnresponse
Explanation of the Code:
Logging:
The logging module is used to track and debug the Lambda function. It logs the event data received, the function version, and the response returned. The INFO level ensures that relevant details are logged for debugging.
The logger.info statements are used to print the function invocation details and the response.
Complex Logic:
The function checks if the name parameter exists in the event data. If not, it defaults to "Guest".
It retrieves the number parameter and doubles the number as an example of computation (i.e., number * 2).
Versioning:
The VERSION variable tracks the version of the Lambda function (e.g., "1.0.0"). This can be updated whenever changes are made to the code.
Steps to Fix and Redeploy the Lambda Function:
1. Delete the Existing Lambda Function:
Before updating the function with the new code, it’s essential to delete the old version of the function in LocalStack to avoid conflicts.
This command deletes the function named myLambdaFunction from LocalStack, preparing for the redeployment with updated code.
2. Recreate the Lambda Function with Updated Code:
Once the old function is deleted, zip the updated code and recreate the function. Make sure the updated lambda_function.py is in your current directory.
Step 1: Zip the Updated Code:
zip lambda_function.zip lambda_function.py
This command creates a .zip file containing the updated lambda_function.py file. This zip file will be used to deploy the new version of the Lambda function.
This command creates a new Lambda function in LocalStack with the updated code:
--function-name myLambdaFunction: Specifies the function name (myLambdaFunction).
--runtime python3.8: Sets the runtime to Python 3.8.
--role arn:aws:iam::000000000000:role/execution_role: Assigns the execution role (this role can be any placeholder role in LocalStack).
--handler lambda_function.lambda_handler: Defines the entry point for the Lambda function (lambda_handler in the lambda_function.py file).
--zip-file fileb://lambda_function.zip: Points to the .zip file containing the updated code.
3. Invoke the Lambda Function with Payload:
Now that the function is updated, you can invoke it by passing a JSON payload. The payload should be contained in a file (e.g., event.json), which includes input data like "name" and "number".
We’ve heard a lot about the term “serverless,” how they work, and the benefits that your application brings. A serverless service in general will not require any server provision to run the application. When you run an application on serverless, users will not have to worry about setting up the operating system, patching, or extending […]
vticloud.io
This article offers a beginner-friendly introduction to AWS Lambda, explaining the service and its configuration for those just starting with serverless computing.
2. AWS Lambda Documentation - Welcome to AWS Lambda
The official AWS documentation provides a comprehensive overview of AWS Lambda, including how to get started, manage functions, and integrate with other AWS services.
A quick tutorial for learning AWS Lambda in 10 minutes. This resource is perfect for those who want to quickly understand the basics of Lambda and its use in cloud applications.
📄 Want to see the output step by step? Check it out here:
🎉 And that's a wrap! Huge congratulations—you’ve just taken your first steps into the powerful world of serverless computing! 🎖️
You now know how to create, configure, and run AWS Lambda functions — all without touching a single server.
💡 I hope this guide helped you! I added a lot of examples and detailed breakdowns because when I started, serverless felt magical and mysterious! ✨
So, I wanted to make it as clear and beginner-friendly as possible. Would love to hear your thoughts and questions!
🔥 Stay tuned for the next article!
We’re diving into Cloud Load Balancing and Auto Scaling — the dynamic duo that keeps your apps lightning fast ⚡ and super resilient 💪 under any traffic!
💬 Did you enjoy this guide?
Drop a comment if it helped, share your favorite Lambda use-cases, or tell me about your first serverless project!
Thanks so much for your appreciation — it really means a lot! 🌟
Actually, this isn't the last article — I still have a few more planned for this series.
After that, I’m thinking of starting new articles like Data Warehousing using MySQL and Big Data Analytics using Hadoop Just figuring out which one to dive into first!
If you have any suggestions on what you'd like me to cover next (or any other topic you think would be interesting), feel free to let me know. Would love to hear your thoughts! ✨
Ah, I saw (6 Part Series) and no notes about the next article so just assumed.
If you have any suggestions on what you'd like me to cover next
I'm just along for the ride. You should write on whatever topic you are most passionate about. Hadoop and Big Data is something I never really got into but it definitely would fit well with the theme you have going here.
Such a great explanation with multiple examples makes it super easy to understand. from creating the lambda function to configuring it and then invoking it, everything was so well structured.
[one little advice: the explanation was spot on but somewhat in the middle (specifically in the serverless computing part) things went bit repetitive (a/to me).]
Yup , i mean till the time I reach to that section , there I found it bit repetitive.
Like you said that it helps you do serverless computing and scale up your architecture…. Etc . All these things have been said earlier with fair amount of explanation.
I restructured it for better flow, added more real-world examples, and removed repetitive parts. I also removed the summary since it felt unnecessarily long.
I expanded the Practical Real-World Example section by adding real company examples — I thought including actual companies would make it even more relatable and impactful! (Check out the Real Companies Using AWS Lambda 🚀 part!)
Let me know what you think of these updates!
Thanks again for your suggestions @denyme24 — they definitely helped me improve the article!
glad you consider those changes, now it is more packed and loaded with real world examples. Great Work :) @madhurima_rawat .
Looking forward to more such blogs.






















 Medium
Medium






That was a very thorough explanation, I'm sure it will be helpful to anyone looking to get started with serverless computing.
Since this is the last article in the series, have you given any thought to what you might write about next?