

I’ve recently started my journey with Apache Flink. As I learn certain concepts, I’d like to share them. One such "learning" is the expansion of array type columns in Flink SQL. Having used ksqlDB in a previous life, I was looking for functionality similar to the EXPLODE function to "flatten" a collection type column into a row per element of the collection. Because Flink SQL is ANSI compliant, it’s no surprise this is covered in the standard.
There are cases where fact data might contain an array column, perhaps with a collection of codes or identifiers that can later be used to join with dimension data. The end goal may be a read-optimized view of these facts to each dimension identified in that area.
The Why
Let’s lay the foundation with a quick review of the terms “fact data” and “dimension data”. Fact data typically contains quantitative data of a business process. In an event streaming world, we can think of event streams as fact data - detailing actions of users or other upstream systems. For instance, an online shopper just completed a purchase. A fact event could contain the item identifiers and quantities of the purchased shopping cart, along with identifying information about the user, additional shipping information, and so forth.
Notice the use of the terms “identifiers” and “identifying” in the fact event data, thus making this event fairly “flat.” There are various reasons for this pattern - avoiding redundant/superfluous information, which makes the events themselves smaller. This design pattern would also provide flexibility to update the detailed information about those identified entities.
These details are known as dimension data, and when joined with fact data provide just that to our event streams - dimensionality. When our user dimension data is joined to these purchase event facts, we can then glean the details about the purchasing user. We now know their name, email address, shipping and billing information, and other contact information pertaining to doing business with them. As for the products purchased, this purchase event can now be joined to detailed product dimension data by the inventory system to earmark the purchased quantities. Meanwhile, the inventory system can update a typo in the description of this product because it’s not reliant on anything in the purchase event other than the identifier of the product(s).
A Sample Use Case
Let’s use the NOAA Weather Service API data model to illustrate this array expansion functionality. The Flink tables described in this example are a result of using Kafka Connect to source data from the REST APIs, apply a set of Single Message Transformations, and write that data to Apache Kafka topics.
Dimension Data
Weather "happens" in specific locations. The NOAA defines these locations as zone entities. A zone describes a geographic location, with multiple forecast offices, radar stations, and (in some cases) time zones. A Flink table holding this data might look something like this:
describe `ws_zones`;
| Column Name | Data Type | Nullable | Extras |
|---|---|---|---|
| zoneId | STRING | NOT NULL | PRIMARY KEY, BUCKET KEY |
| url | STRING | NULL | |
| name | STRING | NULL | |
| zoneType | STRING | NULL | |
| state | STRING | NULL | |
| cwas | ARRAY<STRING> | NULL | |
| forecastOffices | ARRAY<STRING> | NULL | |
| timeZones | ARRAY<STRING> | NULL | |
| radarStation | STRING | NULL | |
| ts | TIMESTAMP_LTZ(3) | NULL | METADATA FROM 'timestamp' |
Fact Data
When a weather alert is created, updated, or expires, the API describes that alert entity with the list of affected zones. A Flink table for active alerts might have a schema such as:
describe `ws_active_alerts`;
| Column Name | Data Type | Nullable | Extras |
|---|---|---|---|
| id | STRING | NOT NULL | PRIMARY KEY, BUCKET KEY |
| areaDesc | STRING | NULL | |
| geocodeSAME | ARRAY<STRING> | NULL | |
| geocodeUGC | ARRAY<STRING> | NULL | |
| affectedZones | ARRAY<STRING> | NULL | |
| sent | TIMESTAMP(3) | NULL | |
| effective | TIMESTAMP(3) | NULL | |
| onset | TIMESTAMP(3) | NULL | |
| expires | TIMESTAMP(3) | NULL | |
| ends | TIMESTAMP(3) | NULL | |
| status | STRING | NULL | |
| messageType | STRING | NULL | |
| category | STRING | NULL | |
| severity | STRING | NULL | |
| certainty | STRING | NULL | |
| urgency | STRING | NULL | |
| event | STRING | NULL | |
| sender | STRING | NULL | |
| senderName | STRING | NULL | |
| headline | STRING | NULL | |
| description | STRING | NULL | |
| instruction | STRING | NULL | |
| response | STRING | NULL | |
| NWSheadline | ARRAY<STRING> | NULL | |
| eventEndingTime | ARRAY<TIMESTAMP(3)> | NULL | |
| expiredReferences | ARRAY<STRING> | NULL | |
| eventTs | TIMESTAMP_LTZ(3) ROWTIME | NULL | METADATA FROM 'timestamp', WATERMARK AS eventTs - INTERVAL '5' MINUTE |
Array Expansion
In the ws_active_alerts table, we see the column geocodeUGC of type ARRAY<STRING>. These codes correlate to the identifiers for the zone entities from the ws_zones dimension table.
| id | geocodeUGC | severity | category | status | onset | effective |
|---|---|---|---|---|---|---|
| urn:oid:2.49.0.1.840.0.e98d53f97bfcd60fcf971e613b85819ae1ec3cbb.005.1 | [TXC183, TXC423, TXC459, TXC499] | Severe | Met | Actual | 2024-05-15 15:45:00.000 | 2024-05-15 15:45:00.000 |
| urn:oid:2.49.0.1.840.0.e98d53f97bfcd60fcf971e613b85819ae1ec3cbb.001.1 | [TXC183, TXC203, TXC365, TXC401] | Severe | Met | Actual | 2024-05-15 15:45:00.000 | 2024-05-15 15:45:00.000 |
In Flink SQL, a cross join is a type of join that returns the Cartesian product of the two tables being joined. The Cartesian product is a combination of every row from the first table with every row from the second table. This feature can be particularly useful when you need to expand an array column into multiple rows.
With that in mind, let’s expand the rows of ws_active_alerts using CROSS JOIN UNNEST. For each row in the ws_active_alerts table, UNNEST flattens the array column geocodeUDC of that row into a set of rows. Then CROSS JOIN joins this new set of rows with the single row from the ws_active_alerts table. So the result of UNNEST could be thought of as a temporary table - for the scope of this operation.
select
active.`id` as `alertId`,
`ActiveAlertsByUgcCode`.geocodeugc as `zoneId`,
active.`event` as `event`,
active.`status` as `alertStatus`,
active.`severity` as `severity`
from ws_active_alerts active
CROSS JOIN UNNEST(active.geocodeUGC) as `ActiveAlertsByUgcCode`(geocodeugc);
The results of this query yield a new row for each zone value of the alert.
| alertId | zoneId | event | alertStatus | severity |
|---|---|---|---|---|
| urn:oid:2.49.0.1.840.0.e98d53f97bfcd60fcf971e613b85819ae1ec3cbb.005.1 | TXC183 | Flood Warning | Actual | Severe |
| urn:oid:2.49.0.1.840.0.e98d53f97bfcd60fcf971e613b85819ae1ec3cbb.005.1 | TXC459 | Flood Warning | Actual | Severe |
| urn:oid:2.49.0.1.840.0.e98d53f97bfcd60fcf971e613b85819ae1ec3cbb.005.1 | TXC499 | Flood Warning | Actual | Severe |
| urn:oid:2.49.0.1.840.0.e98d53f97bfcd60fcf971e613b85819ae1ec3cbb.001.1 | TXC183 | Flood Warning | Actual | Severe |
| urn:oid:2.49.0.1.840.0.e98d53f97bfcd60fcf971e613b85819ae1ec3cbb.005.1 | TXC423 | Flood Warning | Actual | Severe |
Join Facts with Dimensions
The goal here is to answer some location questions with the data on hand.
What are the states affected by a given alert?
How many alerts are active for a given state?
If we join our expanded facts about alerts with the dimension data from the zone definitions, we can find the affected states of each alert.
select
active.`id` as `alertId`,
`ActiveAlertsByUgcCode`.geocodeugc as `zoneId`,
zone.state as `state`
from ws_active_alerts active
CROSS JOIN UNNEST(active.geocodeUGC) as `ActiveAlertsByUgcCode`(geocodeugc)
LEFT JOIN ws_zones zone ON zone.zoneId = `ActiveAlertsByUgcCode`.geocodeugc;
| alertId | zoneId | state |
|---|---|---|
| urn:oid:2.49.0.1.840.0.e98d53f97bfcd60fcf971e613b85819ae1ec3cbb.005.1 | TXC183 | TX |
| urn:oid:2.49.0.1.840.0.e98d53f97bfcd60fcf971e613b85819ae1ec3cbb.005.1 | TXC423 | TX |
| urn:oid:2.49.0.1.840.0.e98d53f97bfcd60fcf971e613b85819ae1ec3cbb.005.1 | TXC459 | TX |
| urn:oid:2.49.0.1.840.0.e98d53f97bfcd60fcf971e613b85819ae1ec3cbb.005.1 | TXC499 | TX |
The results of this join operation could be a new table with the read-optimized data needed by a microservice to answer the question of “give me the active alerts for a given state.”
-- create new table
create table alert_zone_state (
`alertId` STRING,
`zoneId` STRING,
`state` STRING,
PRIMARY KEY (`alertId`, `zoneId`) NOT ENFORCED
) with (
'value.format' = 'avro-registry',
'kafka.cleanup-policy' = 'delete',
'kafka.retention.time' = '10 minutes'
);
-- load that table with the results of the join
insert into alert_zone_state select
active.`id` as `alertId`,
`ActiveAlertsByUgcCode`.geocodeugc as `zoneId`,
zone.state as `state`
from ws_active_alerts active
CROSS JOIN UNNEST(active.geocodeUGC) as `ActiveAlertsByUgcCode`(geocodeugc)
LEFT JOIN ws_zones zone ON zone.zoneId = `ActiveAlertsByUgcCode`.geocodeugc;
select * from alert_zone_state where state is not null;
Here's a screenshot from my Flink SQL Workspace in Confluent Cloud.
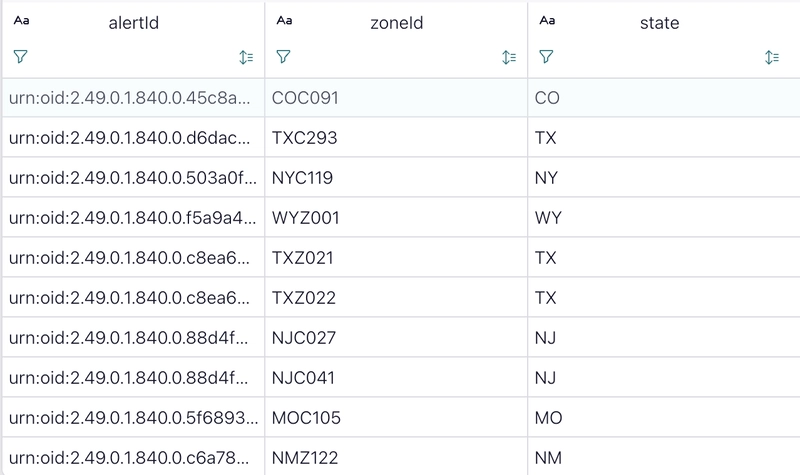
But let's expand on this with a new table to get a count of the distinct active alerts for all states:
-- create a new table
create table alert_counts_for_states (
`state` STRING,
`alertCount` INTEGER,
PRIMARY KEY (`state`) NOT ENFORCED
) with (
'value.format' = 'avro-registry',
'kafka.cleanup-policy' = 'compact'
);
-- load the counts into the new table from the previous table we created
insert into alert_counts_for_states
select
`state`,
cast(count(distinct(`alertId`)) as INTEGER) as `alertCount`
from alert_zone_state where `state` is not null
group by `state`;
-- query the table
select * from alert_counts_for_states;
The results of this query might look like this in my Flink SQL Workspace.
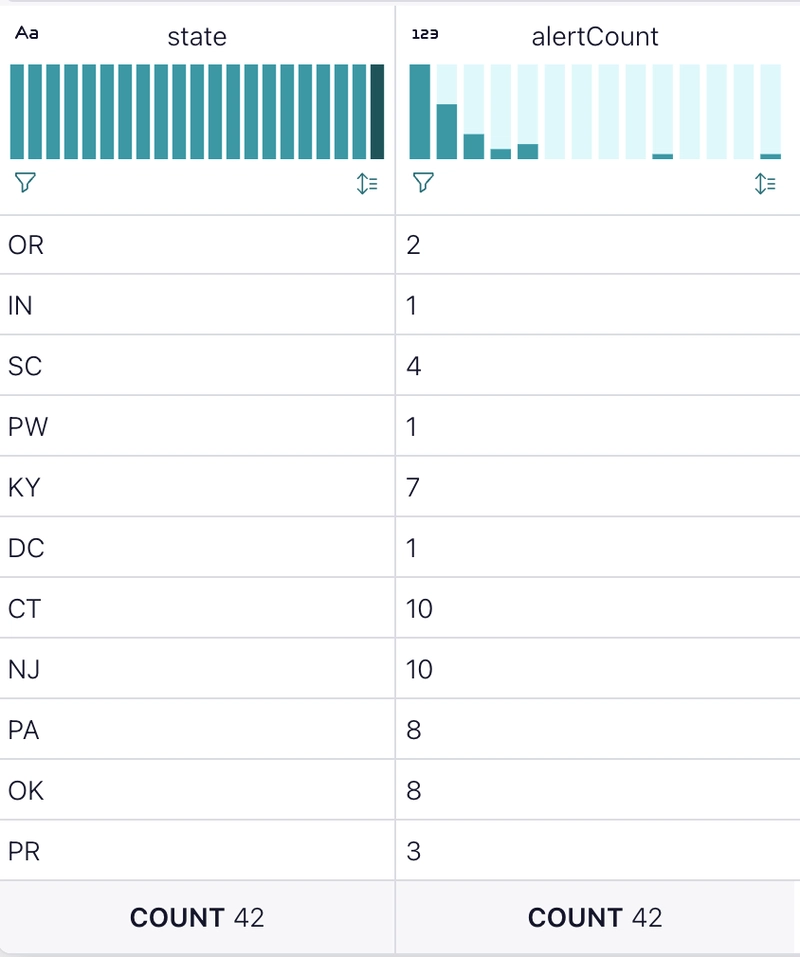
Land the Plane
CROSS JOIN UNNEST proves to be a useful tool to unpack array types in source datasets. We can't always rely on the provider of source data to normalize these raw datasets to meet our application needs.
I hope you find this helpful in your journey with Flink SQL.