

𝗦𝘁𝗿𝗲𝗮𝗺𝗶𝗻𝗴 - sequential movements, processed in real-time.
𝗤𝘂𝗲𝘂𝗶𝗻𝗴 - stored in a queue, processed sequentially.
Choosing between streaming and queuing isn’t just about picking Kafka over RabbitMQ. It’s about making an architectural decision that will define how your system scales, evolves, and handles data over time.
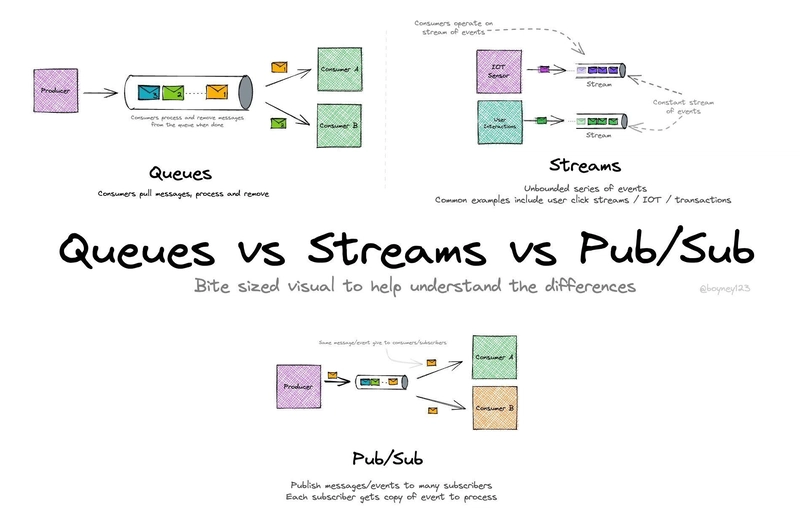
Pick the wrong one, and you’ll feel the consequences for years.
𝗪𝗵𝗲𝗻 𝗧𝗼 𝗖𝗵𝗼𝗼𝘀𝗲 𝗦𝗧𝗥𝗘𝗔𝗠𝗜𝗡𝗚:
- You need historical data replay (e.g., debugging or analytics).
- Your system requires event order guarantees (e.g., processing transactions sequentially).
- Multiple consumers need to read the same event independently.
- You’re handling high-throughput data flows that need efficient processing.
𝗪𝗵𝗲𝗻 𝗧𝗼 𝗖𝗵𝗼𝗼𝘀𝗲 𝗤𝗨𝗘𝗨𝗜𝗡𝗚:
- You need guaranteed task completion (e.g., order processing or background jobs).
- Each task must be processed by only one consumer (e.g., no need for data replay).
- The message should be consumed once and discarded after processing.
- Built-in retries and dead-letter queues offer automatic failure handling.
𝗖𝗼𝗺𝗯𝗶𝗻𝗲 𝗕𝗼𝘁𝗵: 𝗠𝗼𝘀𝘁 𝗦𝘂𝗰𝗰𝗲𝘀𝘀𝗳𝘂𝗹 𝗔𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲𝘀 𝗗𝗼
The most powerful systems leverage both—streaming for real-time processing and queuing for task completion. An example might be:
Real-time tracking systems (using streaming for events like user activity or sensor data).
Task-based systems (using queuing to ensure reliable processing, such as background jobs or transactional workflows).
𝗞𝗲𝘆 𝗥𝗲𝗮𝘀𝗼𝗻𝘀 𝗳𝗼𝗿 𝗠𝗶𝘀𝘂𝘀𝗲
→ Events ≠ Tasks – Queues handle tasks (e.g., payments), while streams handle continuous data (e.g., market prices).
→ Latency Matters – Queues add delays; streams process in real-time.
→ No Replay – Queues discard messages; streams allow reprocessing.
→Tooling Bias – Teams stick to familiar queues instead of streaming solutions like Kafka or Pulsar.
This awesome diagram by @boyney123